

Für Monaten hatte ich in meinem privaten Kubernetes Cluster ein (unvollständiges) Backup das irgendwie funktionierte. Zum Glück 😅 Es war auch keine richtige Backup Strategie dahinter sondern eher verschiedene Proof-of-Concepts. Dieses eigentlich ja nicht vorhandene Backup war mit ein Grund, warum ich nur wiederwillig neue Services im Cluster eingerichtet habe und mir auch ein paar Bauchschmerzen verursacht hat. Ein langsam wachsendes Unbehagen.
Die Anforderungen
Bevor ich angefangen habe eine richtige Backup Strategie im Cluster einzuführen: was sind eigentlich die Anforderungen?
- 3-2-1-Regel: drei Kopien, zwei verschiedene Medien, eines off-site. Industriestandard für "ich verliere keine Daten beim einfachen Disaster".
- Encryption-at-rest: Daten dürfen in keinem Cloud-Storage unverschlüsselt liegen. Selbst wenn Wasabi, meine off-site Location, morgen alle Buckets dumpt, meine Daten bleiben blob-encrypted.
- Local first: Wenn nur eine PVC kaputt ist, will ich nicht hunderte GB übers Internet restoren müssen.
- Wachsendes Vertrauen statt blindem Glauben: Ein Backup, das nie getestet wird, ist kein Backup, sondern reine Hoffnung. Automatisierte Restore-Tests!
- GitOps-kompatibel: Alles muss in YAML passen, alle Secrets müssen verschlüsselt im Git landen, ArgoCD muss alles deployen.
- Monitoring: Ich sollte sehen ob und was passiert. Und wenn etwas nicht richtig passiert, auch eine Notification erhalten.
Meine "alte" Welt: Wasabi-only mit Sidecars
Die Erstgeneration meiner Backups war einfach: jede App, deren Daten ich behalten wollte, bekam einen restic-Sidecar im selben Pod. Ein crond im Sidecar triggerte stündlich restic backup direkt zu Wasabi.
Das hat funktioniert, hatte aber drei Probleme:
- Wasabi-Egress ist nicht "frei", sondern rate-limited. Wasabi bietet kostenlosen Egress, aber nur bis 1:1 mit dem gespeicherten Volumen pro Monat. Bei einem ~180 GB Repo heißt das: 180 GB/Monat Egress frei. Beim Initial-Bootstrap und bei Restores kann das schnell knapp werden, und Wasabi behält sich vor, das Konto zu sperren.
- Wasabi-Abhängigkeit: Ein Wasabi-Outage = keine Backups. Die Hourly-Schedule-Tabelle füllt sich zuverlässig mit Failed-Pods, sobald meine Internetleitung mal eine Stunde wackelte.
- Sidecars sind eng gekoppelt: jeder App-Pod-Restart unterbrach den crond, jede Helm-Chart-Änderung musste die Sidecar-Konfiguration mitschleppen.
Die zweite Generation war ein Refactor zu standalone CronJobs pro App. Schon viel besser, aber die Wasabi-Abhängigkeit blieb.
Meine neue Welt: Lokal first, Wasabi second
Der Schlüssel: Wasabi nicht mehr als Primary verwenden. Wenn das lokale Storage zur Source-of-Truth wird, fallen Egress-Limits, Internet-Latenz und WAN-Outages aus dem kritischen Pfad. Wasabi wird zum Off-Site-Spiegel degradiert 🎉
Der neue Stack sieht so aus:
Workloads (hourly)
|
v
backup-* CronJobs (mariadb, emby, ..., paperless, grafana)
| restic backup ==> rest-server URL
v
rest-server (Pod auf ZFS Node)
| täglich 05:00, rclone copy nach Wasabi
v
Wasabi S3 (Off-site Mirror, replicated cross-region)Die 3-2-1-Regel ist abgedeckt:
- 3 Kopien: lokal auf ZFS, Wasabi eu-central-2, Wasabi eu-west-1 (per Cross-Region-Replication)
- 2 Medien: ZFS-Pool und S3
- 1 off-site: Wasabi (deutlich entfernt vom Homelab)
Die Bausteine
Im Moment sind es sechs CronJobs die alles abdecken, was ich behalten will:
| Target | Quelle | Schedule | Eigenheit |
|---|---|---|---|
| MariaDB | initContainer-Dump ==> PVC | :10 stündlich |
mariabackup-XB-Stream |
| Grafana | Longhorn RWO PVC | :20 stündlich |
podAffinity zur Grafana-Pod |
| Emby | Longhorn RWO PVC | :30 stündlich |
UID 0 (Emby läuft als root) |
| NextPVR | Longhorn RWO PVC | :40 stündlich |
hostNetwork, podAffinity |
| Downloader | hostPath (6 *arr-Apps) | :50 stündlich |
nodeSelector ZFS-Node |
| Paperless | 3 SMB PVCs | :00 stündlich |
uid=1000 SMB-Mount-Option |
Jeder CronJob mountet das gleiche backup.sh aus einer ConfigMap, das via Reflector in jeden Namespace gespiegelt wird. Konfiguration kommt aus einem per-Target-Secret (SOPS-encrypted im Git).
Plus drei Service-CronJobs:
- restic-retentionpolicies (
03:05daily): forget+prune+integrity-check gegen das lokale Repo - backup-restore-test (
04:00Sunday): full Restore Test von jedem Tag in einen Scratch-Volume + Verification - backup-mirror-wasabi (
05:00daily): rclone copy lokales Repo ==> Wasabi
Der REST-Server
Der zentrale Knotenpunkt ist ein restic/rest-server, der ein restic-Repo über HTTP verfügbar macht. Single-Replica Deployment auf die Node mit ZFS Pool mit hostPath: /vol_raidz1/restic-local, htpasswd-Authentifizierung, und nodeSelector-Pinning:
nodeSelector:
node-role/workload: zfs
securityContext:
runAsUser: 65534
runAsGroup: 65534
fsGroup: 65534
runAsNonRoot: true
volumes:
- name: data
hostPath:
path: /vol_raidz1/restic-local
type: DirectoryDer ZFS-Pool gibt mir Compression (zstd) und Snapshot-Möglichkeiten gratis.
Encryption
Lokales Repo und Wasabi-Mirror teilen sich die restic-Verschlüsselung.
Heißt:
rclone copy /local-repo wasabi:bucketist eine reine Datei-Kopie ohne Re-Encryption- Bestehende Files werden geskippt
- Der Mirror ist effizient, nur neue Pack-Files werden übertragen
- Restore funktioniert von beiden Repos identisch
Ich habe lange überlegt, ob das nicht ein Footgun ist (was wenn ich aus Versehen verschiedene Daten unter gleichem Hash erzeuge?). Antwort: kann nicht passieren, weil bei restic der Hash aus dem verschlüsselten Inhalt gebildet wird. Gleicher Hash heißt gleicher Inhalt.
Migration: Bootstrap, InCluster Job
Der Bootstrap der neuen Architektur war der heikelste Teil. Erst wollte ich den Initial-Copy von der Workstation aus per kubectl port-forward machen. Bei 9% Fortschritt hat sich der port-forward dann verabschiedet, kubectl port-forward ist ein reines Debug-Tool, kein Bulk-Transfer-Werkzeug.
Lösung: ein in-cluster OneShot Job, der direkt den ClusterIP-Service ansprach. restic copy --from-repo wasabi:... mit der lokalen URL als Ziel.
Vorteile gegenüber port-forward:
- ClusterIP Service ist robust, port-forward ist fragil
- Workstation kann einfach geschlossen werden, der Job läuft weiter
restic copyist idempotent, bei Abbruch einfach neu starten, schon kopierte Snapshots werden übersprungen
Monitoring & Alerts
Backups, die niemand misst, gibt es nicht. Drei Metric-Schichten:
Pro-Run-Metriken (von backup.sh selbst)
Jeder erfolgreiche Backup Run pusht via Prometheus Pushgateway:
backup_status{status="success"|"failure"}: Exit-Codebackup_duration_seconds: Laufzeit in Sekundenbackup_start_timestamp: Unix-Zeitstempelbackup_snapshot_restore_size_bytes: Größe des frischen Snapshots beim Restore (überrestic stats latest --mode restore-size --json)
Prometheus scrapet alle 15s vom Pushgateway und speichert jeden Scrape historisch. Im Grafana Dashboard zeichnet das pro Backup-Run einen Datenpunkt. Ideal um z.B. Größenveränderungen zu erkennen.
PrometheusRule Alerts
Aktuell sieben Rules in apps/backup-script/k8s.backup-alerts.yaml:
- BackupOverdue:
time() - backup_start_timestamp > 7200für 10m ==> 2 verpasste Slots - BackupFailed:
backup_status{status="failure"} == 1für 5m ==> Letzter Run failed - BackupNeverRun:
absent(...)für 24h ==> Tag hat nie gepusht - BackupRestoreTestFailed: Restore Test scheiterte
- BackupRestoreTestStale: Restore Test seit >9 Tagen nicht gelaufen
- BackupMirrorFailed / BackupMirrorStale: Wasabi-Mirror-Probleme
Die Routes hängen am Alertmanager-Webhook eines selbstgebauten AI-Triagers (claude-alert-kubernetes-analyzer) und an ntfy für Push-Notifications aufs Phone.
Das Grafana Dashboard
Elf Panels: von Top-Stats (Hosts reporting, Healthy, Failed, Stale) über Per-Host-Tabellen mit Zeitstempeln bis hin zu Timeseries für Snapshot-Größe, Backup-Dauer und Time-since-last-backup. Größenveränderungen sind sofort visuell erkennbar.
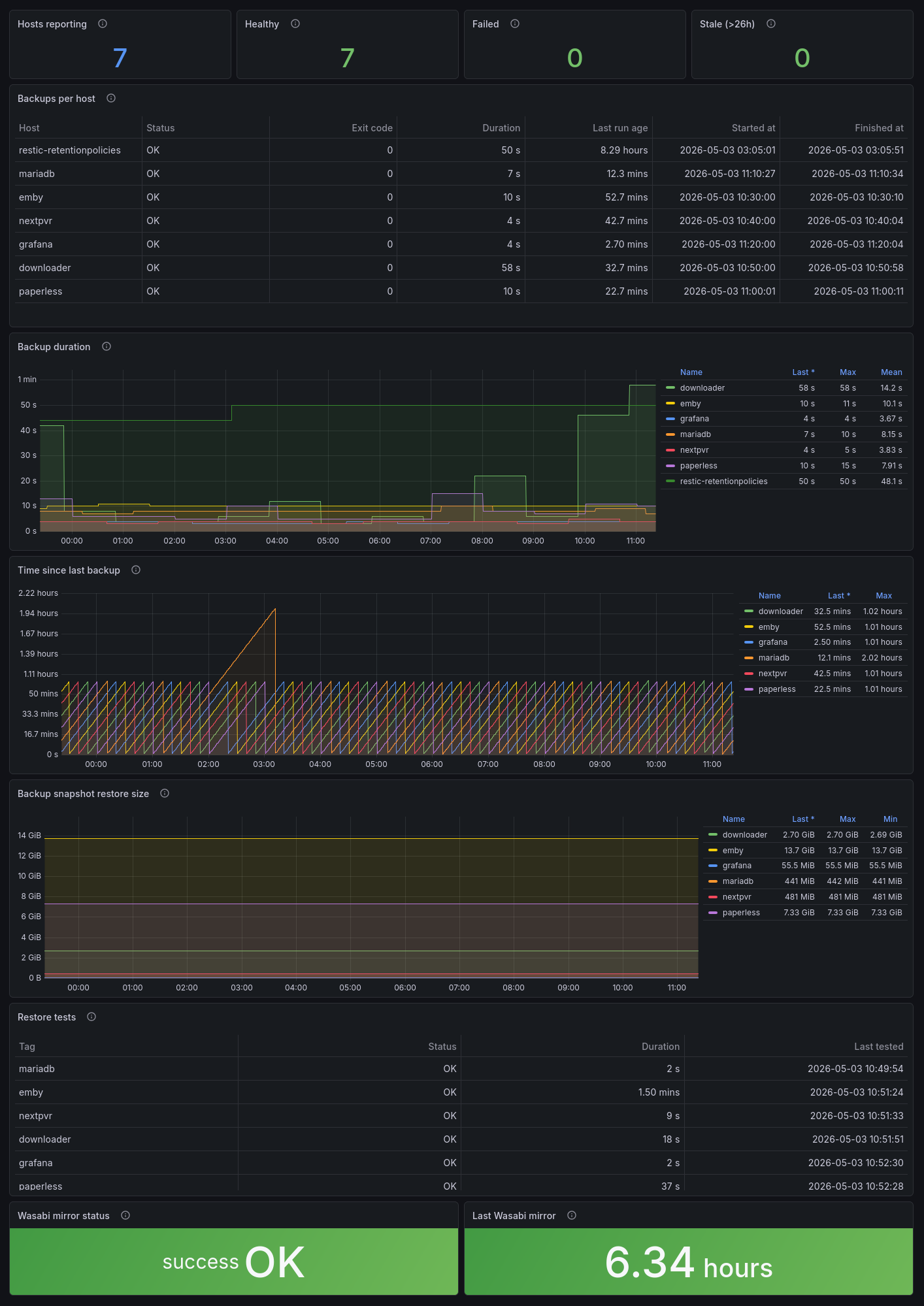
Restore Tests: das eigentliche Vertrauen
Backups sind erst dann Backups, wenn sie restoreable sind. Mein backup-restore-test-CronJob läuft jeden Sonntag und testet jeden letzten snapshot eines Tags (Tag=Label, nicht der Tag wie z.B. Donnerstag):
restic restore latest --tag $TAG --target /restore/$TAGaus dem lokalen rest-server- Tag-spezifische Sanity-Checks:
- SQLite-DBs: existieren und sind nicht leer
- mariabackup-Stream: existiert und ist nicht leer
- Paperless: alle drei Source-Verzeichnisse vorhanden
- Push einer per-Tag
backup_restore_status-Metrik
Da das alles lokal über LAN läuft, kostet jeder Run ~10 Minuten und 0 Egress. Detection-Latenz für eine kaputte Backup-Klasse: maximal eine Woche.
Lessons Learned
Ein paar Dinge, die ich unterwegs gelernt habe:
1. Wasabi-Egress ist nicht "frei", sondern rate-limited. Daily-Heavy-Operations gegen Wasabi (wie täglicher restic check --read-data-subset 5%) können das Konto sperren. Die gleichen Operationen gegen den lokalen rest-server sind kostenlos.
2. NetworkPolicies und Pod Labels müssen synchron sein. Beim Renaming eines Pod Labels (mariadb-backup ==> backup-mariadb) sind alle CiliumNetworkPolicies, die den alten Selektor nutzten, auf einmal "null". Pod hängt mit i/o-Timeouts auf 10.43.0.1:443. Lehre: bei jedem Label Rename alle NPs gleichzeitig mit umstellen. Eigentlich selbstverständlich. Aber es steht hier nicht grundlos 🙈
3. Content-addressed Storage ist genial für Mirrors. Restic + rclone copy ist eine perfekte Kombination, weil restic-Files bei gleichem Inhalt gleichen Namen haben. Kein Risiko für falsche Merges, Dedup wird über Repo-Grenzen hinweg bewahrt.
Was als nächstes kommt
Das System läuft jetzt seit ein paar Wochen stabil. Die nächsten Verbesserungen sind eher Polishing:
- Bessere Retention auf Wasabi: Aktuell sammeln sich orphan Pack-Files, weil der Mirror
rclone copy(kein delete) verwendet. Ein quartalsweiser Cleanup Job wäre nett. - Quartalsweise Wasabi-Restore-Tests: Aktuell verifiziert nur der lokale Restore Test. Off-site Integrity wird nur passiv über
rclone's Größenvergleich abgesichert.
Code & Diskussion
Der gesamte Stack ist Open Source und im k3s-git-ops Repository zu finden. Die Backup-spezifischen Pfade:
- apps/backup-script/: backup.sh ConfigMap, retention CronJob, restore-test, alerts
- apps/backup-rest-server/: rest-server Deployment + Wasabi-Mirror CronJob
apps/<target>/k8s.backup-cronjob.yaml. pro Target
Fragen, Verbesserungsvorschläge, Bugs? GitHub Issues sind willkommen.

t")